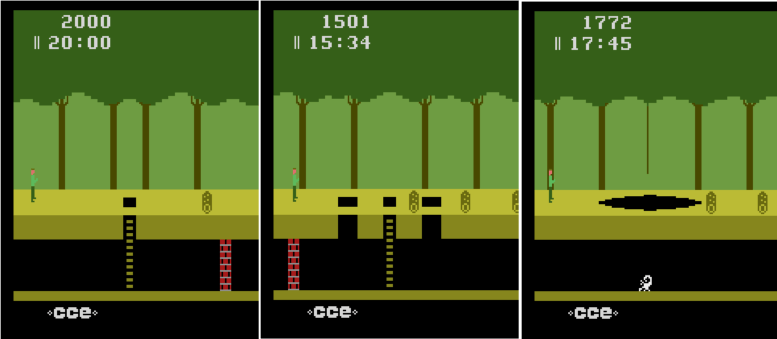
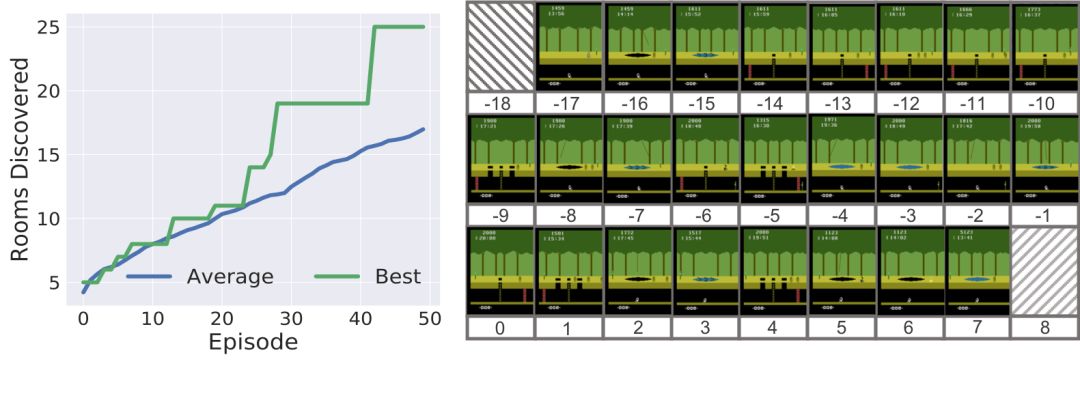
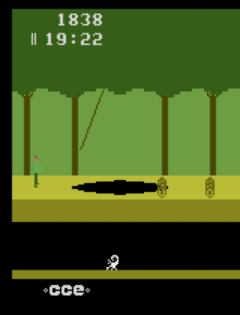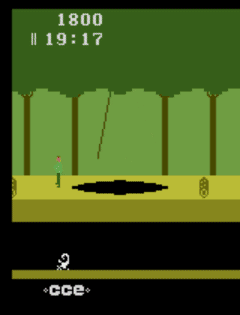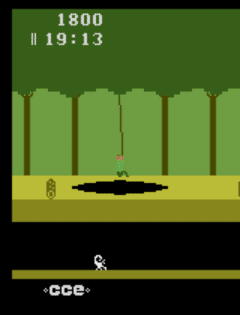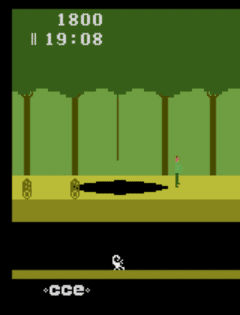
The ability of human beings to learn has always been the goal of artificial intelligence, but for now, the learning speed of the algorithm is far from human. In order to achieve the rate of human learning, Stanford researchers proposed a goal-based strategy reinforcement learning method - SOORL, focusing on strategic exploration and model selection. The following is a compilation of the wisdom brought about. Suppose you let a 12-year-old play an afternoon game of Atari. Even if he had never played before, there is enough game rules before dinner. Pitfall! is one of the highest-selling games on the Atari 2600. It is very difficult. The player controls a character named “Harry†who will walk through the jungle in 20 minutes and find 32 treasures. There are a total of 255 rooms along the way. There are many dangers, such as traps, quicksands, rolling sleepers, flames, snakes, and scorpions. The recent rewards also need to be outside the starting point of the seven scenes, so the bonus distribution is very sparse. Even for humans, it is difficult to control without experience. In-depth neural network and reinforcement learning can be said to have made great progress in imitating human playing games. But these agents often require millions of steps to train, but humans are much more efficient at learning new things. How do we learn efficient rewards quickly and how do we allow agents to do the same? Some people think that people learn and use structural models that explain how the world works, and models that can represent the world with goals rather than pixels, so that agents can gain experience from the same method. Specifically, we assume that there are three elements at the same time: the use of abstract goal-level representations, the ability to learn quickly to learn about world dynamics and support rapid planning models, and the use of forward-looking plans for model-based strategic exploration. Inspired by this idea, we propose the SOORL algorithm. As far as we know, this is the first algorithm that can be rewarded positively in the Atari game Pitfall! It is important that the algorithm does not require human demonstration in this process and can pass through 50 levels. The SOORL algorithm uses powerful prior knowledge instead of traditional deep reinforcement learning algorithms to understand the goals and potential dynamic models in the environment. But compared to the methods that require human demonstration, the SOORL algorithm has much less information. SOORL surpassed the previous goal-oriented reinforcement learning approach in two ways: The agent is actively trying to choose a simple mode that explains how the world works and thus appears to be decisive. The agent uses a model-based approach to active planning. It is assumed that the agent does not calculate a perfect plan to respond to even if it knows how the world will react after it is done. Both of these methods are inspired by the difficulties encountered by humans—there are few prior experiences and limited computational power. Humans must quickly learn to make the right decisions. To achieve this goal, our first method finds that, unlike a complex deep neural network model that requires a lot of data, if a player presses a button and needs little experience to estimate, a simple deterministic model can reduce the plan. The required computing power, although it often goes wrong, is sufficient to achieve good results. Second, playing a game in rewarding and complex video games may require hundreds of steps. For any agent with limited computing power, it is very necessary to make a suitable plan at each step. Difficult, even for 12-year-old children. We use a common and powerful method to do forward planning, that is, Monte Carlo Tree Search, combining it with goal-oriented methods, as an exploration of optimal strategies, and at the same time guiding the agents to learn the environment of the world they do not understand. Pitfall! may be the last player in the Atari game that has not yet been compromised. As stated at the beginning of the article, after the first positive reward in Pitfall! has multiple scenes, players need to be very careful to get it. This requires the agent to have planning ability and ability to predict the future. The average of 50 SOORL agents can unlock 17 scenes. The previous DDQN standard that uses pixels as input and has no strategy to explore can unlock only 6 scenes after 2000 returns. SOORL unlocks up to 25 scenes The histogram below shows the best performance distribution of SOORL algorithm in 100 games during training under different random seeds. It can be seen that SOORL is in most cases not better than all previous methods of deep reinforcement learning. The previous method got the best reward of 0 (although this method was only obtained after 500 or even 5,000 games, and Our method can get the best reward as long as 50 times.) In this case, SOORL can often unlock more rooms than other methods, but it does not achieve higher best results. However, in several games, SOORL received a reward of 2000 points or even 4,000 points, which is the best score obtained without human demonstration. In the case of demonstration, the best score is currently 60,000 points. Although the score is high, this method still requires a lot of prior knowledge, and it also needs a reliable model to reduce the challenges encountered in the exploration process. Here are a few interesting tips for SOORL agents: Fly to the pit Crocodile escaping Dodge the sand pit SOORL still has many limitations. Perhaps the most important drawback is that it requires a reasonable underlying dynamic model to be materialized so that SOORL can perform model selection on this subset. In addition, during the Monte Carlo Tree search, it did not learn and use the value function, which is an important part of the early AlphaGo version. We hope that adding a value function can greatly improve its performance. But apart from these weaknesses, these results are very exciting. Because this model-based reinforcement learning agent can quickly learn in a very sparsely rewarded video game like Pitfall!, it learns how to make the right decisions in simple mode through various strategies.
Anyang Kayo Amorphous Technology Co.,Ltd is located on the ancient city-Anyang. It was founded in 2011 that specializes in producing the magnetic ring of amorphous nanocrystalline and pays attention to scientific research highly,matches manufacture correspondingly and sets the design,development,production and sale in a body.Our major product is the magnetic ring of amorphous nanocrystalline and current transformer which is applied to the communication, home appliances, electric power, automobile and new energy extensively. We are highly praised by our customers for our good quality,high efficiency,excellent scheme,low cost and perfect sale service. High Frequency Transformer,Small And Good Transformer,New Developed Transformer,Useful High Frequency Transformer,Hot Sale Transformer Anyang Kayo Amorphous Technology Co.,Ltd. , https://www.kayoamotech.com


Our high frequency transformer is mainly used in high frequency switching power supply as high frequency switching power transformer, also used in high frequency inverter power supply and high frequency welding machine as high frequency inverter transformer. According to the working frequency,it can be divided into several grades:10KHZ-50KHZ,50KHZ-100KHZ,100KHZ ~ 500KHZ,500KHZ ~ 1MHz,and more than 1MHz