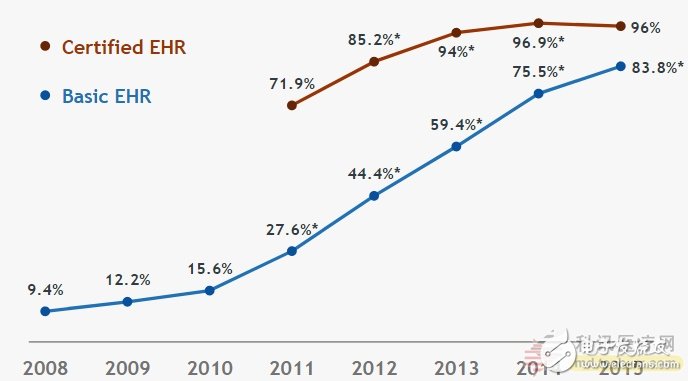
A paper published by google on arXiv, "Scalable and accurate deep learning for electronic health records" (Alvin Rajkomar et al.). In this paper, they present the original EHR records of patients based on the Rapid Health Care Interoperability Resource (FHIR) format, using the deep learning method to accurately predict the occurrence of multiple medical events. The abstract of the paper is as follows: Predictive modeling using electronic health record (EHR) data is expected to drive personalized medicine and improve medical quality. Building predictive statistical models often requires extracting strategic predictors from normalized EHR data, a labor-intensive process that discards most of the information in patient records. We present a representation of all EHR raw records for patients based on the Rapid Health Care Interoperability Resource (FHIR) format. We demonstrate that deep learning methods using this representation accurately predict multiple medical events from multiple centers without the need for data coordination at specific locations. We validated our approach using de-identified EHR data from two US academic medical centers, of which 216,221 adult patients were hospitalized for at least 24 hours. In our proposed sequence format, this EHR data contains a total of 46,864,534,945 data points, including clinical instructions. Deep learning model for predicting in-hospital mortality (AUROC across sites 0.93-0.94), 30-day unplanned readmission rate (AUROC 0.75-0.76), extended hospital stay (AUROC 0.85-0.86), and final diagnosis of all patients (frequency-weighted AUROC 0.90) and so on achieved extremely high accuracy. In all cases, these models performed better than traditional prediction models. We also present a case study of a neural network attribution system that illustrates how clinicians get some transparency in predictions. We believe this approach can create accurate, scalable predictions for a variety of clinical settings, with an explanation of the evidence directly highlighted in the patient's icon. In the course of this research, they believe that if you want to implement machine learning on a large scale, you need to add a protocol buffer tool to the FHIR standard to serialize large amounts of data to disk and allow analysis of large data sets. Yesterday, Google released a message saying that the protocol buffer tool has been open sourced. The following is the content of Google blog post, compiled as follows: Over the past decade, health care data has largely changed from paper documents to digital health records. But there are some key challenges to understanding this data. First, there is no common data representation between different vendors, each vendor is using different methods to build their data; Second, even if you use data from the same vendor's website, there may be big differences, for example, they usually use multiple codes for the same drug to indicate; Third, the data may be distributed across many different tables, some of which have intersections, some contain experimental data, and some contain vital signs. Percentage of non-federal acute care hospitals that employ at least one basic electronic medical record system and have a certified electronic medical record system. Basic's Electronic Health Record (EHR) meets the basic functions of the EHR system. CerTIfied EHR said that the hospital has a legal agreement with the EHR, but it is not equivalent to the EHR system. Fast Healthcare Interoperability Resources (FHIR) is a draft standard for exchanging electronic medical record data formats and data elements and application interfaces organized by the Health Services Seven InternaTIonal. Formulated. This standard has solved most of these challenges: it has a solid, scalable data model built on established Web standards and is rapidly becoming the de facto standard for personal records and bulk data access. But if you want to achieve large-scale machine learning, we need to add something to it: tools that use multiple programming languages, as an efficient way to serialize large amounts of data to disk and allow analysis of large data sets. Today, we are pleased to open up the FHIR standard protocol buffer tool, which solves these problems. The current version supports the Java language, and will soon support languages ​​such as C++, Go, and Python. In addition, support for configuration files and tools to help convert legacy data to FHIR will be available soon. 600Mbps Wireless-wifi Repeater
About
this item
1.
Ideal for
boosting existing network to hard-to reach area, delivering fast and stable
wireless connection, transfer rate up to 600Mbps
2.
Repeater/AP
modes for extending wifi or create wifi hotspot, watch video on line, play
games, online shopping without interference
3.
Activate
passion for your life, mobile devices at full signal, wall mounted design
flexible to place and 7 steps to finish setup
4.
Designed with
mobility and portability, little gadget with great value, One-touch wireless
security encryption with WPS button
5.
Ethernet port
allows the Extender to function as a wireless adapter to connect wired devices,
Compatible with 802.11n/g/b devices
2 Working Modes:(Select
based on your needs)
Repeater Mode
Plug WiFi Booster into your power
socket, easily expand your existing WiFi coverage to signal dead zones
Access Point Mode
Connect your router signal with
Ethernet Cable, cover a wired network to a wireless access point.
600Mbps Wireless-Wifi Repeater,Wifi Amplifier,Wireless Extender,Wifi Booster For Home Shenzhen Jinziming Electronic Technology Co.,LTD , https://www.powerchargerusb.com