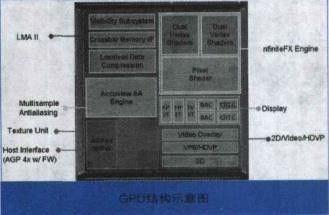
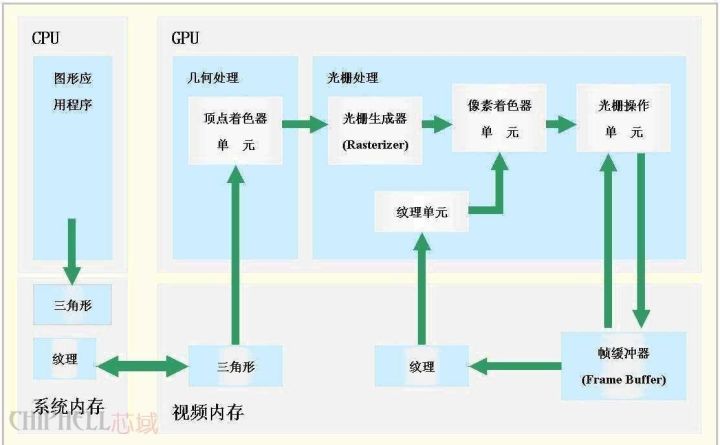
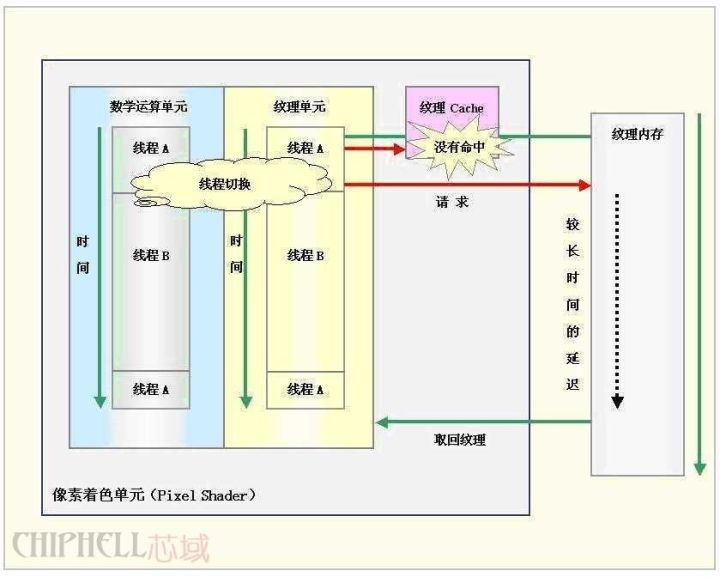
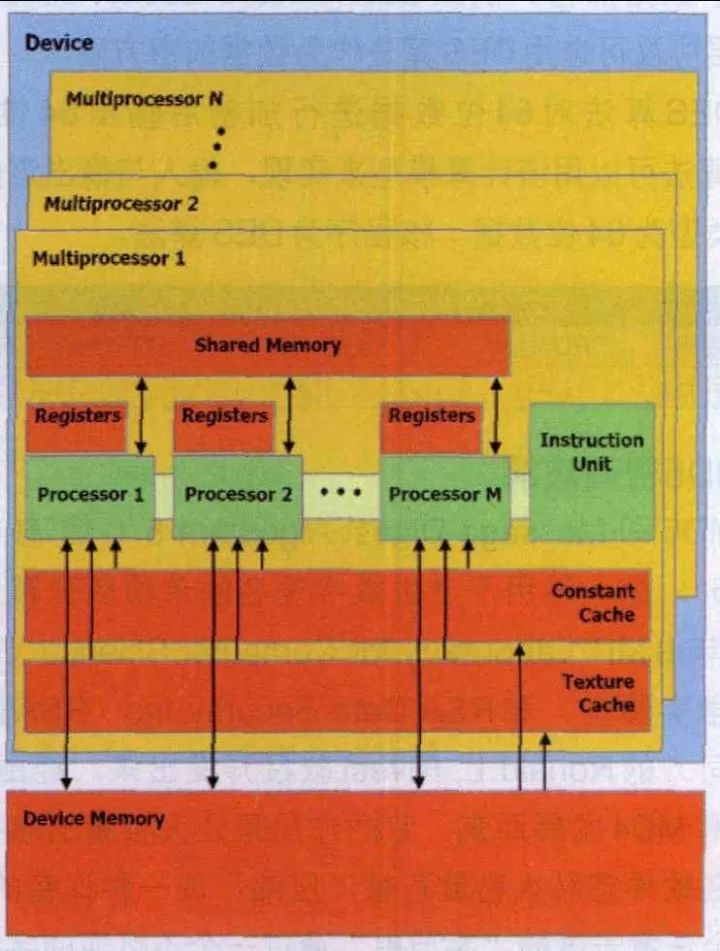
GPU, a shorthand for Graphics ProcessingUnit, is a very important part of modern graphics cards. Its status is consistent with the status of the CPU on the motherboard, and the main task is to speed up the graphics processing. The GPU is the "brain" of the display card, which determines the grade and most of the performance of the graphics card, and is also the basis for the difference between the 2D graphics card and the 3D graphics card. The 2D display chip mainly relies on the processing power of the CPU when processing 3D images and special effects, and is called "soft acceleration". The 3D display chip concentrates the three-dimensional image and special effects processing functions on the display chip, which is also called the "hardware acceleration" function. Today, GPU is no longer limited to 3D graphics processing. The development of GPU general-purpose computing technology has attracted a lot of attention in the industry. It turns out that GPU can provide dozens of times or even more on floating-point computing and parallel computing. Hundreds of times the performance of the CPU, such powerful performance has made the CPU maker boss Intel nervous for the future. When NVIDIA released the GeForce 256 graphics processing chip on August 31, 1999, it first proposed the concept of GPU. The main reason why GPUs are called graphics processors is that it can perform almost all data operations related to computer graphics, which in the past was a patent for CPU. Since the day the GPU was born, its development has not stopped. Due to its unique architecture and superb floating-point computing power, people hope to transplant some general-purpose computing problems to the GPU to improve efficiency. GPGPU (General Purpose Graphic Process Unit), but it is not widely accepted due to its difficulty in development. In 2006, NVIDIA introduced the first GPU (G80) based on Tesla architecture. The GPU has not only been limited to graphics rendering, but has begun to formally move toward general-purpose computing. In June 2007, NVIDIA introduced CUDA (Computer Unified Device Architecture). CUDA is a software and hardware system that uses the GPU as a data parallel computing device. In CUDA's architecture, generic computing is no longer mapped to graphics APIs like the GPGPU architecture of the past. For developers, the development threshold of CUDA is greatly reduced. CUDA's programming language is based on Standard C, so any C-based user can easily develop CUDA applications. Due to these characteristics, CUDA has developed rapidly after its launch and is widely used in petroleum exploration, astronomical calculation, fluid dynamics simulation, molecular dynamics simulation, biological calculation, image processing, audio and video coding and decoding. The GPU is actually a collection of graphics functions, and these functions have hardware implementations, as long as they are used for coordinate transformation and light source processing when objects move in 3D games. Previously, these jobs were carried out with CPUs and specific software. The GPU was in a sense to appear as a protagonist in the graphics process. The above picture is a simple schematic diagram of the GPU structure. A standard GPU mainly includes 2D Engine, 3D Engine, VideoProcessing Engine, FSAA Engine, and Memory Management Unit. Among them, 3DEngine plays a decisive role in 3D computing, which is the soul of modern 3D graphics cards and an important indicator of the difference between GPU levels. Processing flow of data in GPU Let's take a look at how the second generation GPU handles a single picture. First, various physical parameters from the CPU enter the GPU, and the Vertex shader will make basic judgments on the vertex data. If there is no Vertex effect to process, the vertex data goes directly to the T&L Unit for traditional T&L operations to save time and increase efficiency. If you need to deal with various Vertex effects, the Vertex shader will first calculate the various Vertex Programs instructions. The general Vertex Programs often include the effects of past conversion, clipping, illumination, etc., so they are processed by Vertexshader. The effect generally does not require a T&L operation. In addition, when it comes to situations involving surface tessellation (converting surfaces such as bows into polygons or triangles). The CPU can directly pass the data to the Vertex shader for processing. In addition, in the Transform process of DiretX8.0, Vertexshader can complete the elimination of Z value, which is Back Face Culling. This means that in addition to the vertices outside the field of view, the vertices hidden by the points in front of the field of view are also clipped together, which greatly reduces the number of vertices that need to be manipulated. Next, the various data processed by the VertexShader will flow into the SetupEngine, where the arithmetic unit will perform the triangle setting work, which is the most important step in the whole drawing process. The Setup Engine even directly affects the execution performance of a GPU. . The triangle setting process consists of polygons, or replaces the original triangle with a better triangle. In a three-dimensional image, some triangles may be blocked by the triangle in front of it, but at this stage, the 3D chip does not know which triangles will be blocked, so the triangle building unit receives a complete triangle consisting of three vertices. Each corner (or vertex) of a triangle has a corresponding X-axis, Y-axis, and Z-axis coordinate values ​​that determine their position in the 3D scene. At the same time, the setting of the triangle also determines the extent of pixel filling. At this point, the work of VertexShader is complete. In the first generation of GPUs, the set triangles should have been filled into the pixel pipeline with all their parameters for texture filling and rendering, but now it is different, we also broadcast PiexlShader before filling. In fact, the PieXIShader does not exist independently. It is located behind the texture-filling unit. After the data flows into the turbulent pipeline, it enters the texture-filling unit for texture filling. Then, the Piex! Shader unit performs various processing operations through the PiexlShader unit and then enters the pixel. The filling unit performs a specific pink color, and after a fogging operation, a complete picture is completed. It is worth noting that the second-generation GPU introduces independent display data management mechanisms. They are located between the VertexShader, SetuPEngine, and pixel pipelines. The data is transmitted and combined more efficiently, and various invalid values ​​are eliminated. The compression of data and the management of registers, the emergence of this unit plays a crucial role in ensuring the efficiency of the entire GPU. In short, the GPU's graphics (processing) pipeline does the following: (not necessarily in the following order) Vertex processing: At this stage, the GPU reads vertex data describing the appearance of the 3D graphics and determines the shape and positional relationship of the 3D graphics based on the vertex data to establish a skeleton of the 3D graphics. In GPUs that support the DX8 and DX9 specifications, this is done by a hardware-implemented Vertex Shader. Rasterization calculation: The image actually displayed by the display is composed of pixels. We need to convert the points and lines on the above generated image to corresponding pixels through a certain algorithm. The process of converting a vector graphic into a series of pixel points is called rasterization. For example, a mathematically represented slash segment is eventually transformed into a staircase of consecutive pixels. Texture map: The polygon generated by the vertex unit only constitutes the outline of the 3D object, and the texture mapping work completes the map on the multi-deformed surface. In layman's terms, the surface of the polygon is pasted with the corresponding image, thereby Generate "real" graphics. The TMU (Texture Mapping Unit) is used to do this. Pixel Processing: At this stage (during rasterization of each pixel) the GPU performs the calculation and processing of the pixels to determine the final properties of each pixel. In GPUs that support the DX8 and DX9 specifications, this is done by a hardware-implemented PixelShader. Final output: The output of the pixel is finally completed by the ROP (rasterization engine), and after one frame is rendered, it is sent to the memory frame buffer. Today's games, from the generation of images, probably require the following four steps: 1, Homogeneouscoordinates (homogeneous coordinates) 2, Shading models (shadow modeling) 3, Z-Buffering (Z-buffer) 4, Texture-Mapping (material map) In these steps, the display part (GPU) is only responsible for completing the third and fourth steps, while the first two steps are mainly done by the CPU. Moreover, this is only the generation of 3D images, and does not include complex AI operations in the game. Scene switching operations and so on... Undoubtedly, these elements also require the CPU to complete, which is why when running a large game, when the scene is switched, the strong graphics card will pause. Next, let's take a quick look at how the data between the CPU and the GPU interact. First, the model is read from the hard disk, and the CPU classifies the polygon information to the GPU. The GPU then processes the polygons visible on the screen from time to time, but the texture is only the wireframe. After the model comes out, the GPU puts the model data into the video memory, and the graphics card also pastes the material for the model and gives the color on the model. The CPU accordingly obtains the information of the polygon from the video memory. The CPU then calculates the outline of the shadow produced after the illumination. After the CPU is calculated, the work of the graphics card is again, that is, filling the shadow with a deep color. It should be noted that no matter how many game graphics cards are used, the light and shadow are calculated by the CPU. The GPU only has 2 jobs and 1 polygon is generated. 2 is the color on the polygon. Traditional GPUs are based on SIMD architecture. SIMD is Single Instruction Multiple Data, single instruction and multiple data. In fact, this is well understood, the traditional VS and ALU in the PS (arithmetic logic unit, usually there will be one ALU in each VS or PS, but this is not certain, for example, two G70 and R5XX) can be in one cycle The operation of the four channels of the vector is completed internally (ie simultaneously). For example, a 4D instruction is executed, and the ALU in the PS or VS performs corresponding calculations on the four attribute data corresponding to the fixed point and the pixel of the instruction. This is the origin of SIMD. We call this ALU a 4D ALU for the time being. It should be noted that although the 4D SIMD architecture is very suitable for processing 4D instructions, the efficiency will be reduced to 1/4 when encountering 1D instructions. At this point, the resources of ALU 3/4 are idle. In order to improve the resource utilization of PSVS when performing 1D 2D 3D instructions, GPUs in the DirectX9 era usually use 1D+3D or 2D+2D ALU. This is the Co-issue technology. This ALU is still the same as the traditional ALU for the calculation of 4D instructions, but it is much more efficient when it comes to 1D 2D 3D instructions, such as the following instructions: ADD R0.xyz , R0, R1 //This instruction adds the x, y, and z values ​​of the R0 and R1 vectors to the R0 result. ADD R3.x , R2, R3 //This instruction adds the w value of the R2 R3 vector and assigns the result to R3. For the traditional 4D ALU, it obviously takes two cycles to complete, the first cycle ALU utilization is 75%, and the second cycle utilization is 25%. For the 1D+3D ALU, these two instructions can be combined into one 4D instruction, so it only takes one cycle to complete, and the ALU utilization is 100%. But of course, even with co-issue, the ALU utilization rate is unlikely to reach 100%, which involves the parallelism of the instructions, and more intuitively, the above two instructions obviously cannot be 2D+2D ALU one cycle. Complete, and again, two 2D instructions cannot be completed by the 1D+3D ALU cycle. Traditional GPUs are obviously not very flexible in handling non-4D instructions. GPU multithreading and parallel computing The function of the GPU is updated very quickly. On average, a new generation of GPUs is born every year, and the computing speed is getting faster and faster. The GPU's computing speed is so fast, mainly because the GPU is tailor-made for real-time graphics rendering, with two main features: ultra-long pipeline and parallel computing. GPU execution is fast, but when running instructions that fetch texture data from memory (since memory access is a bottleneck, this operation is slow), the entire pipeline has a long pause. Inside the CPU, multi-level Cache is used to increase the speed of accessing memory. Cache is also used in the GPU, but the Cache hit rate is not high, and only Cache can't solve this problem. Therefore, in order to keep the pipeline busy, GPU designers use multi-threading. When the pixel shader encounters an instruction to access the texture for thread A of a pixel, the GPU will immediately switch to another thread B to process the other pixel. Wait until the texture is retrieved from memory and switch to thread A. For example, if you need to assemble a car, 10 time units, divide it into 10 pipeline stages, and assign a time unit to each stage, then one assembly line can produce one car per time unit. Obviously, the production of the pipeline mode is ideally ten times faster than the serial mode. But there is a premise to use this method, thread A and thread B have no data dependency, which means no communication between the two threads. If thread B needs thread A to provide some data, even if it switches to thread B, thread B is still inoperable and the pipeline is still idle. Fortunately, graphics rendering is essentially a parallel task. Whether the vertex data sent by the CPU to the GPU or the pixel data generated by the GPU raster generator are irrelevant, they can be processed independently in parallel. Moreover, vertex data (xyzw) and pixel data (RGBA) are generally represented by quaternions, which is suitable for parallel computing. The SIMD instruction is specifically set in the GPU to process the vector, and four channels of data can be processed at the same time. The SIMD instructions are very simple to use. In addition, the texture slice can only be read, or can only be written, and is not readable and writable, thus solving the read and write conflicts of memory access. The GPU's constraint on memory usage further ensures the smooth completion of parallel processing. In order to further increase the degree of parallelism, the number of pipelines can be increased. In the GeForce 6800 Ultra, there are up to 16 sets of pixel shader pipelines and 6 sets of vertex shader pipelines. Multiple pipelines can be operated under centralized control of a single control unit or independently. In the Single Instruction Multiple Data Stream (SIMD) architecture, the GPU supports data parallel computing through single instruction multiple data (SIMD) instruction types. In the structure of a single instruction multiple data stream, a single control component dispatches instructions to each pipeline, and the same instructions are executed simultaneously by all processing components. For example, the NVIDIA 8800GT graphics card contains 14 sets of multiprocessors, each of which has 8 processors, but each set of multiprocessors contains only one instruction unit (InstruetionUnit). Another type of control structure is Multi-Instruction Multiple Data Stream (MIMD), each of which can execute different programs independently of other pipelines. The GeForce 6800Ultra vertex shader pipeline is controlled using MIMD mode, and the pixel shader pipeline uses the SIMD structure. MIMD can execute branch programs more efficiently, and the SIMD architecture can cause very low resource utilization when running conditional statements. However, SIMD requires less hardware, which is an advantage. Most of the transistors in the CPU are mainly used to build control circuits and Caches, and only a small number of transistors are used to perform the actual calculations. The control of the GPU is relatively simple, and the demand for the Cache is small, so most of the transistors can form various special circuits and multiple pipelines, which makes the GPU's computing speed have a breakthrough leap, and has an amazing handling of floating-point operations. ability. Now the technological advancement of the CPU is slower than Moore's Law, and the GPU is running faster than Moore's Law, doubling its performance every six months. With the further development and improvement of CUDA, the computing power of the GPU will be further strengthened. Researchers have also begun to use CUDA to perform a variety of scientific simulations and calculations using GPUs that are several times the CPU's floating-point computing power. GPUs are dedicated to solving problems that can be represented as data parallel computing—programs that execute in parallel on many data elements, with extremely high computational density (ratio of mathematical operations to memory operations). The GPU computing model is to combine the CPU and GPU in the heterogeneous collaborative processing computing model. The serial portion of the application runs on the CPU, while the heavy-duty portion of the computation is accelerated by the GPU. From the user's perspective, the application just runs faster. Because the application takes advantage of the high performance of the GPU to improve performance. In the past few years, the floating point performance of GPUs has risen to the level of Teraflop. The success of GPGPU has made programming work related to the CUDA parallel programming model very easy. In this programming model, application developers can modify their applications to find computationally intensive program kernels, map them to the GPU, and let the GPU process them. The rest of the application is still handled by the CPU. To map certain functions to the GPU, developers need to rewrite this functionality, using parallelism in programming, adding "C" language keywords to exchange data with the GPU. The developer's task is to start tens of thousands of threads at the same time. GPU hardware can manage threads and thread scheduling. "GPUs have evolved into a mature stage that can easily execute real-world applications and run faster than they would with multi-core systems. The future computing architecture will be parallel core GPUs in parallel with multi-core CPUs. Running hybrid system." The Institute of Genomics of the Chinese Academy of Sciences will transplant the BLAST algorithm, which is widely used in the field of bioinformatics, to the GPU. This is a set of sequence query algorithms and software packages for DNA and protein sequence databases. Although BLAST processes a small number of sequences at a slow rate, with the rapid development of DNA side-sequence technology, researchers can obtain massive sequence data in just a few days, so the analysis of these data becomes a bottleneck. Through the transition from serial to parallel, the BLAST algorithm has been successfully implemented on the GPU, greatly improving efficiency. According to the results of the Chinese Academy of Sciences, a key module in the BLAST software based on the NVIDIA Tesla platform runs 35 times faster than a single CPU. Based on the GPU, the Chinese Academy of Sciences established a supercomputing system. Compared with the general system, the operating system cost has dropped from about 200 million yuan to less than 20 million yuan, the peak energy consumption has dropped from about 1.5 megawatts to less than 0.3 megawatts, and the floor space has also been significantly reduced, but its efficiency is very high. . In the amplification and optimization simulation program of Sinopec's clean gasoline process, when the internal structure is optimized, the processing efficiency of a single CPU can simulate 4 to 5 seconds of real time per day, while a single GPU can simulate 3 to 5 in one hour. Second real time. The fastest supercomputer in China, Tianhe-1, also uses a GPU processor, and two-thirds of its computing power is provided by GPU processors.
The Screen Protector has a self-healing technology that can automatically eliminate small scratches on the Protective Film within 24 hours. Significantly reduce dust, oil stains and fingerprint smudges, anti-scratch.
The Screen Protection Film is very suitable for curved or flat screens. The Soft Hydrogel Film perfectly matches the contour of your device. Will not affect any functions of the phone.
The Ultra-Thin Protective Film with a thickness of only 0.14mm uses 100% touch screen adaptive screen touch screen technology, complete touch screen response, high-tech technology makes the screen touch to achieve zero delay, ultra-thin material brings you "realism".
The Protection Film has excellent clarity and incredible toughness, providing a high level of clarity and a glass-like surface, highlighting the sharpness of the most advanced smartphone display images and bright colors.
If you want to know more about Self Repair Screen Protector products, please click the product details to view the parameters, models, pictures, prices and other information about Self Repair Screen Protector.
Whether you are a group or an individual, we will try our best to provide you with accurate and comprehensive information about the Self Repair Screen Protector!
Self-healing Protective Film, Self-repairing Screen Protector,Self-healing Screen Protector, Self-Healing Hydrogel Film,Hydrogel Film Screen Protector Shenzhen Jianjiantong Technology Co., Ltd. , https://www.jjttpucuttingplotter.com