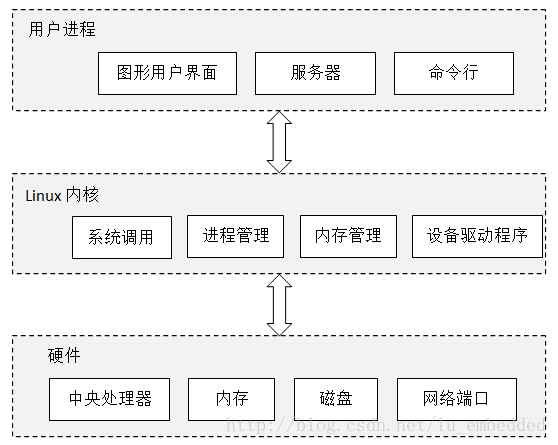
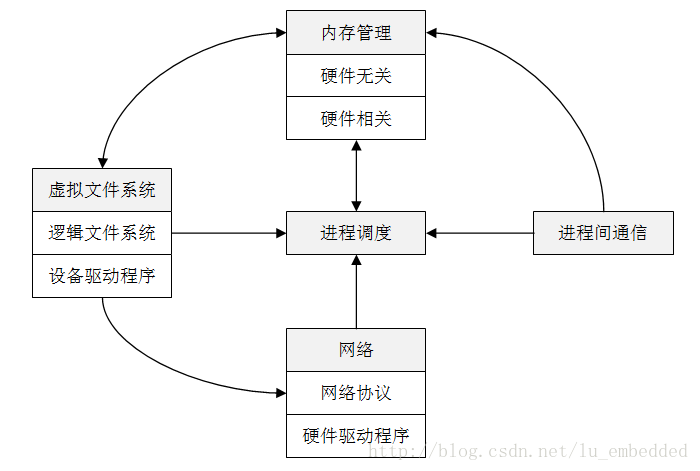
As one of the representatives of modern operating systems, the Linux operating system is very complex, and there are many dazzling internal components running synchronously and communicating with each other. For beginners, I think the best way to understand how the operating system works is to use abstract thinking to understand, that is, you can ignore most of the details for the time being. Just like a car, you usually don't care about fixing the engine's mounting bolts in the car, and you don't care who you are building. If you are a passenger, you may only care about how to open or close the door, how to fasten the seat belt and where the car will take you. If you are a driver, you need to know more details, such as how to control the throttle, brakes and shifts, and how to deal with unexpected situations. If you are a maintenance engineer or a car designer, you need a deeper understanding of the car structure and how it works. Let's try to understand the driving problem by using "abstract thinking". First we can abstract "a car on the road" into three parts: car, road and driving operation. In this way, driving this thing is much simpler, we almost only need to know the driving operation. If the road is bumpy, it will not blame the car itself and its own driving skills. Instead, we will ask why this road is so bad, and we must definitely follow this path. Similarly, in the software development process, developers usually don't have to care too much about the internal structure of the components they need to use. They only care about which components can be used and how they should be used. As with automotive components, each component can contain complex technical details, but we can ignore these details for a while and focus on what these components do in the system. In fact, this "layered thinking" formed by abstract thinking is applicable in both computer technology and other social production activities. Linux operating system hierarchy Let's take a look at what components can be broken down into abstractions by abstraction and where they are located between the user and the hardware system. In short, the Linux operating system can be roughly divided into three layers, as shown in the following figure, the bottom layer is the hardware system, including CPU, memory, hard disk, network card, etc.; above the hardware system is the kernel, which is the core of the operating system, the kernel Responsible for managing the hardware system while providing an operational interface for the application; the user process here represents all the programs running on the computer, they run in the user space, and are managed by the kernel. The biggest difference between the kernel and the user process is that the kernel runs in kernel mode (also called kernel mode), and the user process runs in user mode (also called user mode). Code running in kernel mode has unrestricted access to the central processor and memory, which means that the kernel can do whatever it wants, which is very dangerous because the kernel process can easily crash the entire system. Therefore, in order to improve system stability and limit the access rights of the process to the central processing unit and memory, the concept of user mode is proposed. Generally, we refer to the space that only the kernel can access as kernel space, and the space that the user process can access is called user space. With this limitation, even if a user process crashes while it is running, it will not have a serious impact on the entire system. Kernel mode and user mode In fact, kernel mode and user mode require processor support. The essential difference between a kernel program and a user program is that the kernel program can execute privileged instructions in addition to executing most of the general-purpose instructions. When it comes to computer instructions, you have to mention RISC (Reduced Instruction Set Computer) and CISC (Complex Instruction Set Computer). We know that Intel's x86 architecture chip uses CISC, and ARM architecture chip. Then use RISC. That is to say, the switching between kernel mode and user mode and the implementation of the mode depend on the CPU instruction set architecture. Intel's x86 processor uses the Ring level for access control, which is divided into four levels, namely Ring0~Ring3. The Ring0 layer has the highest privilege and the Ring3 layer has the lowest privilege. According to Intel's original idea, the application works in the Ring3 layer and can only access the space of the Ring3 layer; the operating system works on the Ring0 layer and can access all layers of space; while other drivers work with the Ring1 and Ring2 layers, each layer only Can access this layer and the lower level of data. This design can effectively guarantee the stability and security of the operating system. However, modern operating systems, including Windows and Linux, do not use Layer 4 permissions, only the Ring0 and Ring3 layers, which correspond to kernel space and user space. Therefore, once the driver is loaded, it runs on the Ring0 layer and has the same permissions as the operating system kernel. Unlike the x86 architecture, ARM does not have Ring0~Ring3, and there is no Root mode or non-Root mode. As we all know, ARM has seven working modes, namely usr (user mode, User), fiq (fast interrupt mode, FIQ), irq (external interrupt mode, IRQ), svc (administrative mode, Supervisor), abt (data access abort mode) , Abort), und (undefined command abort mode, Undef) and sys (system mode, System). The other six processor modes except User mode are called Privileged Modes. In privileged mode, the program can access all system resources, and can also arbitrarily switch between processor modes. In addition, there is the Monitor mode brought by Security Extensions introduced in ARM v6, and the Hyp mode brought by Virtualization Extensions introduced in ARM v7. More complex for the ARM v8 architecture, which defines two Execution States, AArch32 state and AArch64 state. At the same time, four Exception Levels are defined for permission control, which are EL0~EL3. For AArch32, ARMv8 defines nine PE modes (that is, the nine working modes mentioned above) to determine execution permissions without using EL; for AArch64, PE mode is not supported. (For more information on processor architecture, please refer to the relevant manual). The role of memory In addition to the CPU, memory can be said to be the most important part of the hardware system. The memory stores the bit data of 0 or 1. The kernel and the process are also running in the memory. They are a series of bit data sets in the memory. The data input and output of all peripheral devices are completed through the memory. The CPU processes the data in memory just like an operator. It reads instructions and data from memory and writes the result back to memory. Almost all operations of the Linux kernel are related to memory. For example, the memory is divided into many blocks, and the state information of these blocks is maintained. Each process has its own memory block, and the kernel guarantees that each process only Use its own memory block. Linux kernel The Linux kernel uses a monolithic structure. The entire kernel is a single, very large program. This allows the various parts of the system to communicate directly and improve the system's speed. However, the embedded system has small storage capacity and resources. Limited features do not match. Therefore, in the embedded system, another architecture called Microkernel is often used, that is, the kernel itself only provides some basic operating system functions, such as task scheduling, memory management, interrupt processing, etc. Additional features like file systems and network protocols run in user space and can be traded off based on actual needs. This can greatly reduce the size of the kernel, easy to maintain and transplant. For a macro kernel operating system such as Linux, a complete Linux kernel consists of five subsystems: process scheduling, memory management, virtual file system, network interface, and interprocess communication. · Process Scheduling (SCHED) controls the access of the process to the CPU. When you need to choose the next process to run, the scheduler chooses the most worthwhile process to run. A runnable process is actually a process that only waits for CPU resources. If a process is waiting for other resources, the process is an unrunnable process. Linux uses a relatively simple priority-based process scheduling algorithm to select new processes. · Memory Management (MM) allows multiple processes to share the main memory area securely. Linux memory management supports virtual memory, that is, programs running on a computer. The total amount of code, data, and stack can exceed the actual memory size. The operating system simply keeps the currently used program blocks in memory, and the rest of the program blocks. It is kept on disk. When necessary, the operating system is responsible for exchanging blocks between disk and memory. Memory management is logically divided into hardware-independent parts and hardware-related parts. The hardware-independent part provides process mapping and logical memory swapping; the hardware-related part provides a virtual interface for memory management hardware. · The Virtual File System (VFS) hides the details of various hardware and provides a unified interface for all devices. VFS provides dozens of different file systems. Virtual file systems can be divided into logical file systems and device drivers. Logical file system refers to the file system supported by Linux, such as ext2, fat, etc. Device driver refers to the device driver module written for each hardware controller. · Network Interface (NET) provides access to a variety of network standards and support for a variety of network hardware. Network interfaces can be divided into network protocols and network drivers. The network protocol part is responsible for implementing every possible network transmission protocol. The network device driver is responsible for communicating with the hardware device, and each possible hardware device has a corresponding device driver. · Interprocess Communication (IPC) supports various communication mechanisms between processes. Inter-process communication is mainly used to control synchronization, data sharing and exchange in user space between different processes. Since unused user processes have different process spaces, communication between processes is achieved by means of a kernel transfer. In general, when a process waits for a hardware operation to complete, it will be suspended; when the hardware operation is completed, the process is resumed, and the process of coordinating this process is the communication mechanism between processes. The structure of the Linux kernel subsystem is shown in the following figure. The process is scheduled at the center, and all other subsystems depend on it because each subsystem needs to suspend or resume the process. In general, when a process waits for a hardware operation to complete, it is suspended; when the operation is actually completed, the process is resumed. For example, when a process sends a message over the network, the network interface needs to suspend the sending process until the hardware successfully completes the sending of the message. After the message is successfully sent out, the network interface returns a code to the process indicating the operation. Success or failure. Other subsystems rely on process scheduling for similar reasons. The dependencies between the various subsystems are as follows: Relationship between process scheduling and memory management: The two subsystems depend on each other. In a multi-program environment, the program must run a process for it to run, and the first thing to create a process is to load the program and data into memory. The relationship between interprocess communication and memory management: The interprocess communication subsystem relies on memory management to support a shared memory communication mechanism. This mechanism allows two processes to access a common memory area in addition to their own private space. The relationship between the virtual file system and the network interface: The virtual file system supports the Network File System (NFS) using the network interface and also supports the RAMDISK device with memory management. The relationship between memory management and virtual file system: memory management uses virtual file system to support exchange, swap process (swapd) is scheduled by scheduler, which is the only reason that memory management depends on process scheduling. When a memory map accessed by a process is swapped out, memory management issues a request to the file system and, at the same time, suspends the currently running process. In addition to these dependencies, all subsystems in the kernel depend on some common resources. These resources include the processes used by all subsystems. For example: the process of allocating and freeing memory space, the process of printing warnings or error messages, the system's debugging routines, and so on. Four aspects of kernel management The Linux kernel is responsible for managing the following four aspects: · Process: The kernel determines which process can use the CPU. Memory: The kernel manages all memory, allocates memory for processes, manages shared memory between processes, and free memory. · Device driver: As the interface between the hardware system (such as disk) and the process, the kernel is responsible for manipulating the hardware device. System calls and support: Processes typically communicate with the kernel using system calls. Process management The process management design process starts, pauses, resumes, and terminates. Startup and termination are straightforward, but it's relatively complicated to explain how the process uses the CPU during execution. In modern operating systems, many processes seem to be running at the same time. For example, you can open a web browser and spreadsheet application on your desktop at the same time. However, although they seem to be running at the same time, the processes behind these applications are not exactly running at the same time. Let's imagine that in a computer system with only one CPU, there may be many processes that can use the CPU, but only one process can use the CPU in any given time period. So in fact, multiple processes use the CPU in turn, each process pauses after using it for a period of time, and then let another process use it, in turn, in turn, the time unit is milliseconds. One process gives up the CPU usage rights to another process called a context switch. The process has enough time to complete the main computational work during its time period (in fact, the process usually completes its work in a single time period). Since the time period is very short, so short that we are not aware of it, in our opinion, the system is running multiple processes at the same time (we call it multitasking). The kernel is responsible for context switching. Let's take a look at the scenario below to understand how it works. (1) The CPU clocks each process, stops the process when it is finished, and switches to kernel mode, where the kernel takes over control of the CPU. (2) The kernel records the current CPU and memory status information, which is needed to recover the stopped process. (3) The kernel performs tasks in the previous time period (such as obtaining data from input and output devices, disk read and write operations, etc.). (4) The kernel is ready to execute the next process, selecting an execution from the ready process. (5) The kernel prepares the CPU and memory for the new process. (6) The kernel notifies the CPU of the time period during which the new process is executed. (7) The kernel switches the CPU to user mode and hands over the CPU control to the new process. Context switching answers a very important question, when does the kernel run? The answer is: the kernel runs in the time slot gap when the context switches. In a multi-CPU system, the situation is a bit more complicated. If the new process will run on another CPU, the kernel does not need to give up the current CPU usage rights. However, in order to maximize the efficiency of all CPU usage, the kernel will use some other way to obtain CPU control. Memory management The kernel manages memory during context switching, which is a very complicated task because the kernel guarantees all of the following conditions: (1) The kernel needs its own proprietary memory space, and other user processes cannot access it; (2) each user process has its own dedicated memory space; (3) one process cannot access the proprietary memory space of another process; (4) The memory can be shared between user processes; (5) Some memory space of the user process can be read-only; (6) By using disk swap, the system can use more memory space than the actual memory capacity. The new CPU provides MMU (Memory Management Unit). The MMU uses a memory access mechanism called virtual memory, that is, the process does not directly access the actual physical address of the memory, but makes the process appear to be usable through the kernel. The memory of the entire system. When the process accesses the memory, the MMU intercepts the access request and then converts the memory address to be accessed into the actual physical address through a memory map (or a page table). The kernel needs to initialize, maintain, and update this address map. For example, when a context switches, the kernel transfers the memory map from the process being moved out to the process being moved into the process. Device driver and device management For the device, the role of the kernel is relatively simple. Usually the device can only be accessed in kernel mode (for example, the user process requests the kernel to power off the system), because improper access to the device may crash the system. Another reason is that there is no uniform programming interface between different devices, even for similar devices (such as two different network cards). So device drivers are traditionally part of the kernel, providing as much as possible a uniform interface for user processes to simplify the work of developers. System calls and system support The kernel also provides additional functionality to user processes. For example, a system call (system call or syscall) performs some work for a process that they are not good at or can't. Opening, reading, and writing files all involve system calls. The two system calls fork() and exec() are important for us to understand how the process starts. (1) fork(): When the process calls fork(), the kernel creates a copy that is almost identical to the process. (2) exec (): When the process calls exec (program), the kernel starts the program to replace the current process. Except for init, all user processes in Linux are started with fork(). In addition to creating a copy of an existing process, in most cases you can also use exec() to start a new process. A simple example is when you run the ls command from the command line to display the contents of the directory. When you type ls in a terminal window, the shell in the terminal window calls fork() to create a copy of the shell, which then calls exec(ls) to run ls. In addition to traditional system calls, the kernel provides many other functions for user processes, the most common being virtual devices. Virtual devices are physical devices for user processes, but they are all implemented in software. So from a technical point of view, they don't need to exist in the kernel, but in reality many of them exist in the kernel. For example, a virtual device such as the kernel's random number generator (/dev/random) is much more difficult to implement if it is implemented by a user process. User space As mentioned earlier, the memory allocated by the kernel to the user process is called user space. Because a process is simply a state in memory. (User space can also refer to all memory occupied by all user processes) Most of the operations in Linux happen in user space. Although all processes are the same from a kernel perspective, they actually perform different tasks. The user process is in a basic service layer relative to the system components. The underlying service layer provides the tool services (also known as middleware) required by the upper-level applications, such as mail, print, and database services. Top-level components can focus on completing user interactions and complex functions. Of course, components can also be called from each other. Although the concepts of the bottom layer, the top layer, the middle layer, etc. are mentioned here, in reality they have no obvious boundaries in the user space. In fact, many user space components are also difficult to classify, such as Web servers and databases, you can classify them as upper-level components, or as middle-tier components. In addition, technically, the user process still needs to access the virtual device by using the system call to open the device, so the process can never avoid dealing with the system call.
This Solder Wire is with activated resin flux,It enjoys excellent weld ability,which can be divided into RA and RMA.which is made from extremely high purity raw materials.
Sn63/Pb37,Sn60/Pb40,Sn50/Pb50,Sn45/Pb55,Sn40/Pb60,Sn30/Pb70
Flux-Cored Solder Wire,Solder Welding Wire,Lead Free Solder Wire,Silver Solder Wire Shaoxing Tianlong Tin Materials Co.,Ltd. , https://www.tianlongspray.com